
To promote the upcoming Winja CTF 2021 competition which is to be held during Nullcon 2021, Winja released its 1st online quiz challenge on 19 Dec on its Twitter handle as part of its promotional events. Participants were expected to understand the regular expressions and choose the most appropriate answer.
I participated in this quiz and answered correctly. This blog post is to explain the strategy I used to answer this quiz.
Contents
- The Question
- Absolute URL Examples
- What is Regular Expressions?
- Decoding Regex Elements
- Quiz Solution
- One More Way to Check
- The Answer
The Question
To extract absolute URLs from source code, which of the following regular expressions cannot be used:
- http(s)*://[^”]*
- http[s]?://[^”’]+
- [\w]+[s]?[/:]{3}[^”’]+
- [\w]+[s]?[^”’]+
- [\w]+[s]?://[^”’]+
Absolute URL Examples
https://example.com/blah
https://example.com/
http://example.com/blah/blah2
What is Regular Expressions?
A regular expression is an object that describes a pattern of characters. Regular expressions are used to perform “pattern-matching” and “search-and-replace” functions on text. It is also referred to as regex or regexp.
Decoding Regex Elements
For beginners, let’s see a quick explanation of the elements used in building the 5 regular expressions that were part of the quiz.
1. ()
2. \*
3. []
4. ^
5. ?
6. +
7. \w
8. {}
Parentheses () are used for grouping. They can be used to create (capturing) or (?:non-capturing) groups.
An asterisk * is a special character that can match 0 or more occurrences of a regular expression. Together, they can be used to match string variations.
http(s)* — It will match both http and https
A character class (or character set ) [] can be used to match only one out of several characters. This can be achieved by placing the range of characters that we want to match, between square brackets.
[fh]t(t)*p — It will match both ftp and http
Typing a caret ^ after the opening square bracket will negate the character class, thus, matching any character that is not in the character class.
https://[^”’]* — It will match all strings that start with the text https:// and will match all the following characters as long as the character is not a double quote or a single quote.
A character class followed by a question mark ? will match 0 or more occurrences of the specified characters, i.e., either one of the specified characters can be present, or none of them could be present in the matched string. Without a question mark, at least one of the characters must be matched from the specified character set.
[fh]t[t]?p — It can match both ftp and http
A plus sign + will match at least one or more occurrences of the preceding character or the specified regular expression (if grouped in a set of parentheses).
https://[^”]+ — It will match all strings that start with the text https:// only if the following character is not a double quote. It will match all the following characters as long as the character is not a double quote.
The \w meta-character matches word characters, i.e., it is equivalent to character class [a-zA-Z0–9_] in ASCII character set.
[\w]+ — It will match http and https but not http://
Finally, the curly braces {m,n} can be used as an occurrence indicator to match the preceding item at least m times, but not more than n times.
http[:/]{3} — It will match all of the following patterns http:// or http::: or http/// or http//: or http/:/
Now that we have learned how to read regular expressions, let’s interpret the 5 listed quiz options.
Quiz Solution
- Download the source code of any random website. I am choosing view-source:https://blog.shivamsaraswat.com/
- Open the downloaded text content in Visual Studio Code (or any other text editor that supports regular expressions)
- Enable regular expression search (Alt+R, in VS code)
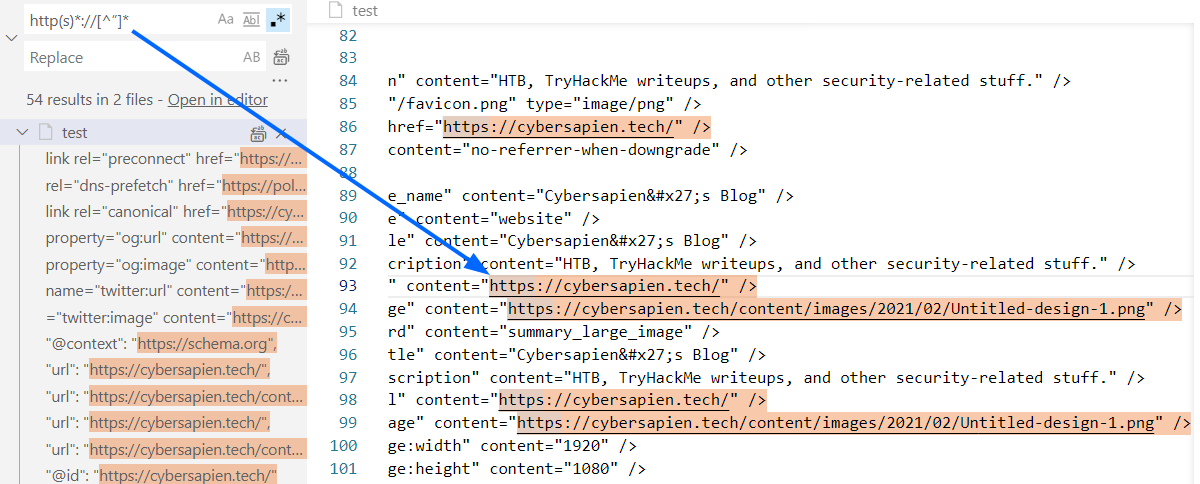
Now, let’s test the first regular expression, and analyze the results:
http(s)*://[^”]*
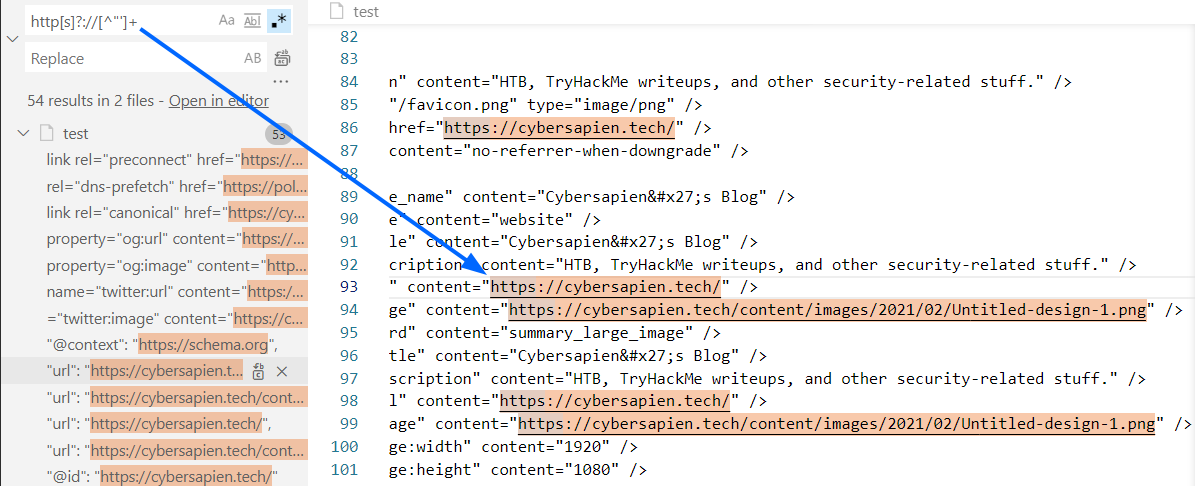
Now, test the second regular expression, and analyze the results:
http[s]?://[^”’]+
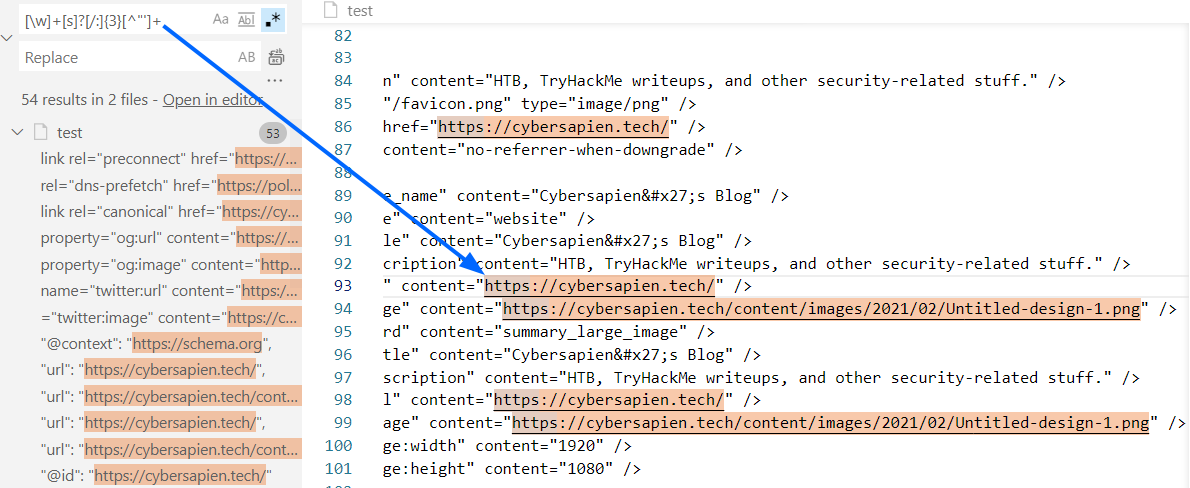
Now, test the third regular expression, and analyze the results:
[\w]+[s]?[/:]{3}[^”’]+
Now, test the fourth regular expression, and analyze the results:
[\w]+[s]?[^”’]+
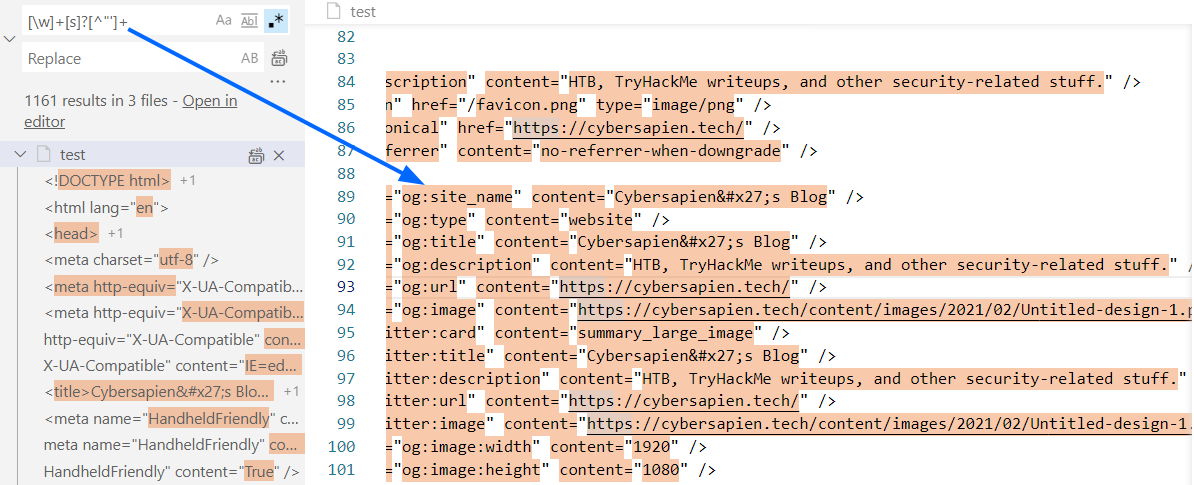
- It looks different from other options as it selects almost whole text, not just absolute URL. This regex is not containing slash (/) and colon (:), so it will not be able to check for URL, it will check for almost whole text.
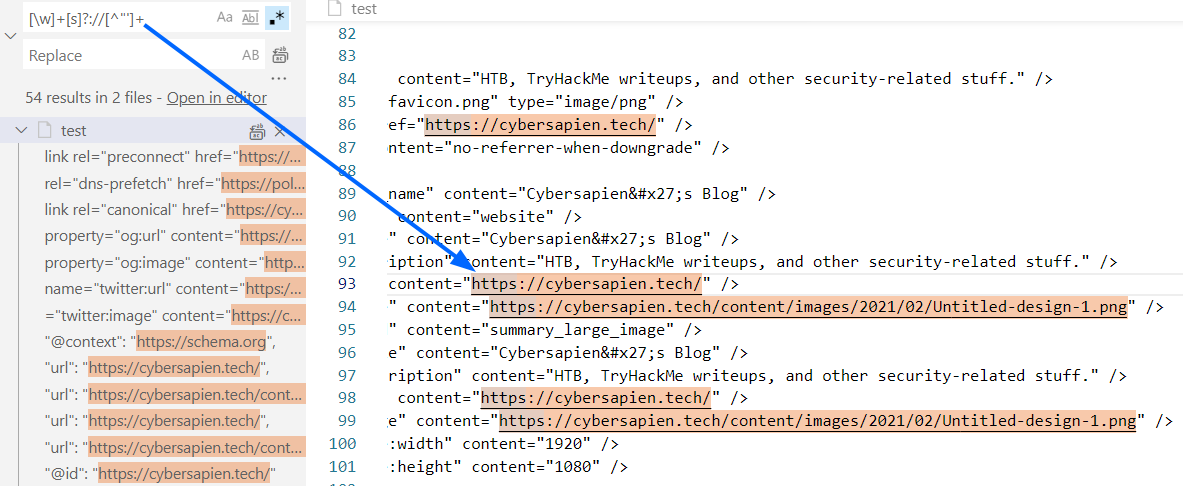
Now, test the final option:
[\w]+[s]?://[^”’]+
One More Way to Check
Let’s test these regex with Python code.
import re
myString = "This is my tweet check it out https://example.com/blah"
print(re.search("(?P<url>http(s)*://[^''']*)", myString).group("url"))
print(re.search("(?P<url>http[s]?://[^''']+)", myString).group("url"))
print(re.search("(?P<url>[\w]+[s]?[/:]{3}[^''']+)", myString).group("url"))
print(re.search("(?P<url>[\w]+[s]?[^''']+)", myString).group("url"))
print(re.search("(?P<url>[\w]+[s]?://[^''']+)", myString).group("url"))
Note: If you want a deep explanation of the code, then check this reference link.
Output —
https://example.com/blah
https://example.com/blah
https://example.com/blah
This is my tweet check it out https://example.com/blah
https://example.com/blah
So here you can see that all the regex are able to extract the absolute URL except the 4th regex which is printing the whole text.
The Answer
So it is clear that, fourth option did not meet our expectations of identifying the absolute URLs correctly. In fact, it was incapable of identifying any URL pattern at all. So it cannot be used to extract absolute URLs from any source code.
Thus, the correct answer is option number 4.
I hope, this post helped you to solve this CTF easily and you must have learned something new.
Feel free to contact me for any suggestions and feedbacks. I would really appreciate those.
Thank you for reading!
You can also Buy Me A Coffee if you love the content and want to support this blog page!